“Let’s use Kubernetes!” Now you have 8 problems
If you’re using Docker, the next natural step seems to be Kubernetes, aka K8s: that’s how you run things in production, right?
Well, maybe. Solutions designed for 500 software engineers working on the same application are quite different than solutions for 50 software engineers. And both will be different from solutions designed for a team of 5.
If you’re part of a small team, Kubernetes probably isn’t for you: it’s a lot of pain with very little benefits.
Let’s see why.
Everyone loves moving parts
Kubernetes has plenty of moving parts—concepts, subsystems, processes, machines, code—and that means plenty of problems.
Multiple machines
Kubernetes is a distributed system: there’s a main machine that controls worker machines. Work is scheduled across different worker machines. Each machine then runs the work in containers.
So already you’re talking about two machines or virtual machines just to get anything at all done. And that just gives you … one machine. If you’re going to scale (the whole point of the exercise) you need three or four or seventeen VMs.
Lots and lots and lots of code
The Kubernetes code base as of early March 2020 has more than 580,000 lines of Go code. That’s actual code, it doesn’t count comments or blank lines, nor did I count vendored packages. A security review from 2019 described the code base as follows:
“…the Kubernetes codebase has significant room for improvement. The codebase is large and complex, with large sections of code containing minimal documentation and numerous dependencies, including systems external to Kubernetes. There are many cases of logic re-implementation within the codebase which could be centralized into supporting libraries to reduce complexity, facilitate easier patching, and reduce the burden of documentation across disparate areas of the codebase.”
This is no different than many large projects, to be fair, but all that code is something you need working if your application isn’t going to break.
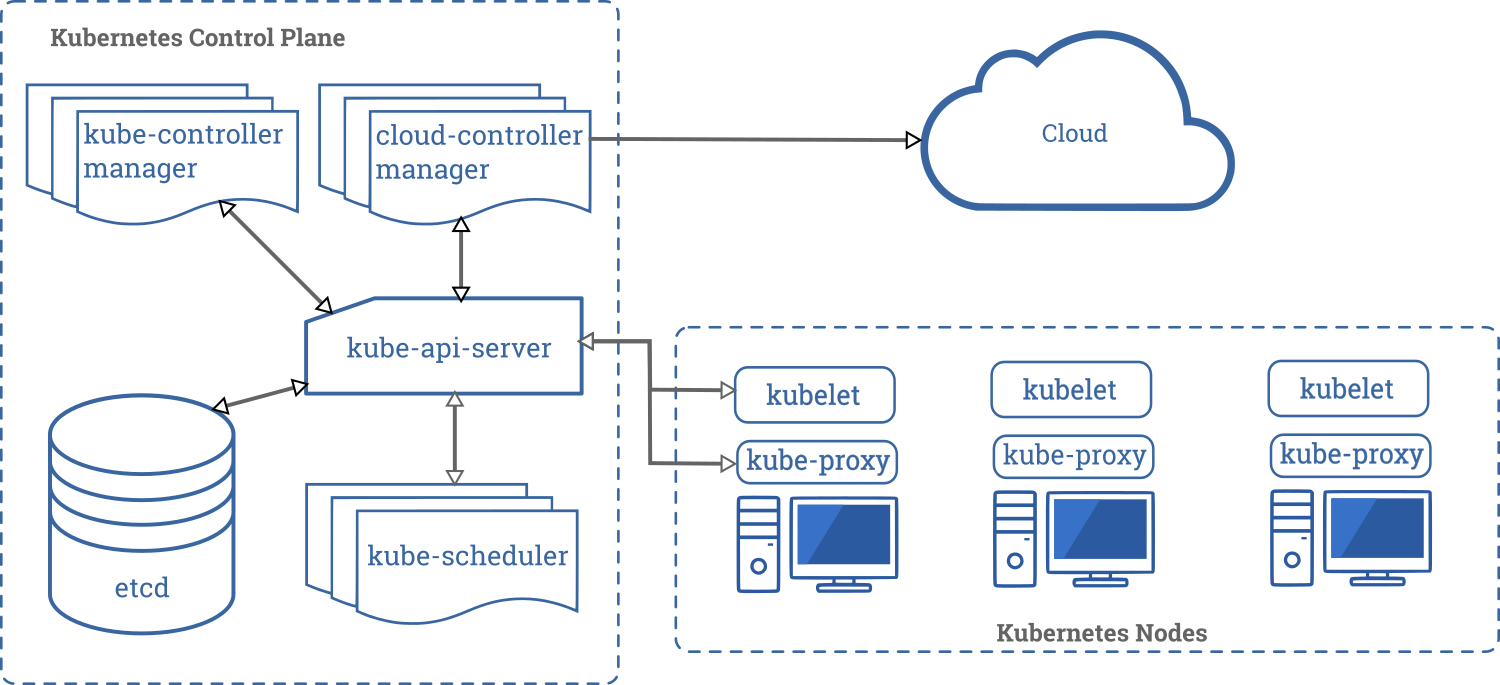
Architectural complexity, operational complexity, configuration complexity, and conceptual complexity
Kubernetes is a complex system with many different services, systems, and pieces.
Before you can run a single application, you need the following highly-simplified architecture (original source in Kubernetes documentation):
The concepts documentation in the K8s documentation includes many educational statements along these lines:
In Kubernetes, an EndpointSlice contains references to a set of network endpoints. The EndpointSlice controller automatically creates EndpointSlices for a Kubernetes Service when a selector is specified. These EndpointSlices will include references to any Pods that match the Service selector. EndpointSlices group network endpoints together by unique Service and Port combinations.
By default, EndpointSlices managed by the EndpointSlice controller will have no more than 100 endpoints each. Below this scale, EndpointSlices should map 1:1 with Endpoints and Services and have similar performance.
I actually understand that, somewhat, but notice how many concepts are needed: EndpointSlice, Service, selector, Pod, Endpoint.
And yes, much of the time you won’t need most of these features, but then much of the time you don’t need Kubernetes at all.
Another random selection:
By default, traffic sent to a ClusterIP or NodePort Service may be routed to any backend address for the Service. Since Kubernetes 1.7 it has been possible to route “external” traffic to the Pods running on the Node that received the traffic, but this is not supported for ClusterIP Services, and more complex topologies — such as routing zonally — have not been possible. The Service Topology feature resolves this by allowing the Service creator to define a policy for routing traffic based upon the Node labels for the originating and destination Nodes.
Here’s what that security review I mentioned above had to say:
“Kubernetes is a large system with significant operational complexity. The assessment team found configuration and deployment of Kubernetes to be non-trivial, with certain components having confusing default settings, missing operational controls, and implicitly defined security controls.”
Development complexity
The more you buy in to Kubernetes, the harder it is to do normal development: you need all the different concepts (Pod, Deployment, Service, etc.) to run your code. So you need to spin up a complete K8s system just to test anything, via a VM or nested Docker containers.
And since your application is much harder to run locally, development is harder, leading to a variety of solutions, from staging environments, to proxying a local process into the cluster (I wrote a tool for this a few years ago), to proxying a remote process onto your local machine…
There are plenty of imperfect solutions to choose; the simplest and best solution is to not use Kubernetes.
Microservices (are a bad idea)
A secondary problem is that since you have this system that allows you to run lots of services, it’s often tempting to write lots of services. This is a bad idea.
Distributed applications are really hard to write correctly. Really. The more moving parts, the more these problems come in to play.
Distributed applications are hard to debug. You need whole new categories of instrumentation and logging to getting understanding that isn’t quite as good as what you’d get from the logs of a monolithic application.
Microservices are an organizational scaling technique: when you have 500 developers working on one live website, it makes sense to pay the cost of a large-scale distributed system if it means the developer teams can work independently. So you give each team of 5 developers a single microservice, and that team pretends the rest of the microservices are external services they can’t trust.
If you’re a team of 5 and you have 20 microservices, and you don’t have a very compelling need for a distributed system, you’re doing it wrong. Instead of 5 people per service like the big company has, you have 0.25 people per service.
But isn’t it useful?
Scaling
Kubernetes might be useful if you need to scale a lot. But let’s consider some alternatives:
- You can get cloud VMs with up to 416 vCPUs and 8TiB RAM, a scale I can only truly express with profanity. It’ll be expensive, yes, but it will also be simple.
- You can scale many simple web applications quite trivially with services like Heroku.
This presumes, of course, that adding more workers will actually do you any good:
- Most applications don’t need to scale very much; some reasonable optimization will suffice.
- Scaling for many web applications is typically bottlenecked by the database, not the web workers.
Reliability
More moving parts means more opportunity for error.
The features Kubernetes provides for reliability (health checks, rolling deploys), can be implemented much more simply, or already built-in in many cases. For example, nginx can do health checks on worker processes, and you can use docker-autoheal or something similar to automatically restart those processes.
And if what you care about is downtime, your first thought shouldn’t be “how do I reduce deployment downtime from 1 second to 1ms”, it should be “how can I ensure database schema changes don’t prevent rollback if I screw something up.”
And if you want reliable web workers without a single machine as the point of failure, there are plenty of ways to do that that don’t involve Kubernetes.
Best practices?
There is no such thing as best practices in general; there are only best practices for a particular situation. Just because something is trendy and popular doesn’t mean it’s the right choice for you.
In some situations Kubernetes is a really great idea. In others it’s a timesink with no benefit.
Unless you really need all that massive complexity, there are wide variety of tools that will do just as well: from Docker Compose on a single machine, to Hashicorp’s Nomad for orchestration, to Heroku and similar systems, to something like Snakemake for computational pipelines.
