Estimating and modeling memory requirements for data processing
Whether it’s a data processing pipeline or a scientific computation, you will often want to figure out how much memory your process is going to need:
- If you’re running out of memory, it’s good to know whether you just need to upgrade your laptop from 8GB to 16GB RAM, or whether your process wants 200GB RAM and it’s time to do some optimization.
- If you’re running a parallelized computation, you will want to know how much memory each individual task takes, so you know how many tasks to run in parallel.
- If you’re scaling up to multiple runs, you’ll want to estimate the costs, whether hardware or cloud resources.
In the first case above, you can’t actually measure peak memory usage because your process is running out memory. And in the remaining cases, you might be running with differents inputs at different times, resulting in different memory requirements.
What you really need then is model of how much memory your program will need for different input sizes. Let’s see how you can do that.
Measuring peak memory usage
When you’re investigating memory requirements, to a first approximation the number that matters is peak memory usage. If your process uses 100MB of RAM 99.9% of the time, and 8GB of RAM 0.1% of the time, you still must ensure 8GB of RAM are available. Unlike CPU, if you run out of memory your program won’t run slower—it’ll crash.
How do you measure peak memory of a process?
On Linux and macOS you can use the standard Python library module resource:
from resource import getrusage, RUSAGE_SELF
print(getrusage(RUSAGE_SELF).ru_maxrss)
On Linux this will be measured in KiB, on macOS it’ll be measured in bytes, so if your code is running on both you’ll want to make it consistent.
On Windows you can use the psutil library:
import psutil
print(psutil.Process().memory_info().peak_wset)
This will return the peak memory usage in bytes.
For simple cases, then, you can just print that information at the end of your program, and you’ll get peak memory usage.
Estimating and modeling peak memory usage
What happens if you can’t actually run your program to completion, or if you expect multiple inputs size with correspondingly varied memory requirements? At this point you need to resort to modeling.
The idea is to measure memory usage for a series of differently sized inputs. You can then extrapolate memory usage for different and/or larger datasets based on the input size.
Let’s consider an example, a program that does image registration, figuring out two similar images are offset from each other in X, Y coordinates. In general, we’d expect memory usage to scale with image size, so we’ll tweak the program to support different image sizes, and have it report peak memory usage when it’s done:
import sys
from resource import getrusage, RUSAGE_SELF
import numpy as np
from skimage import data
from skimage.feature import register_translation
from scipy.ndimage import fourier_shift
from skimage.transform import rescale
# Load and resize a sample image included in scikit-image:
image = data.camera()
image = rescale(image, int(sys.argv[1]), anti_aliasing=True)
# Register the image against itself; the answer should
# always be (0, 0), but that's fine, right now we just care
# about memory usage.
shift, error, diffphase = register_translation(image, image)
print("Image size (Kilo pixels):", image.size / 1024)
print("Peak memory (MiB):",
int(getrusage(RUSAGE_SELF).ru_maxrss / 1024))
We can then run this program with multiple input image sizes:
$ python image-translate.py 1
Image size (Kilo pixels): 256.0
Peak memory (MiB): 116
$ python image-translate.py 2
Image size (Kilo pixels): 1024.0
Peak memory (MiB): 176
$ python image-translate.py 3
Image size (Kilo pixels): 2304.0
Peak memory (MiB): 277
$ python image-translate.py 4
Image size (Kilo pixels): 4096.0
Peak memory (MiB): 417
We now have the following numbers for memory usage:
| Kilo pixels | Peak RAM in MiB |
|---|---|
| 256 | 116 |
| 1024 | 176 |
| 2304 | 277 |
| 4096 | 417 |
Modeling memory usage
At this point we get a sense of memory usage: there’s a fixed minimum, just for running Python and importing all the code, and then it seems like memory grows linearly as the number of pixels increases.
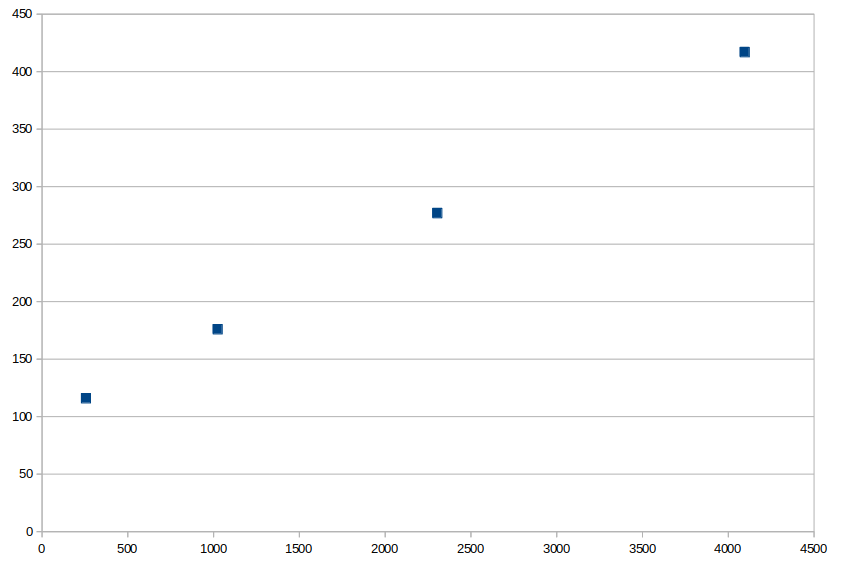
Given the memory usage seems linear with input, we can build a linear model using NumPy:
>>> import numpy as np
>>> np.polyfit([256, 1024, 2304, 4096], [116, 176, 277, 417], 1)
array([7.84278101e-02, 9.59186047e+01])
>>> def expected_memory_usage(image_pixels):
... return 7.84e-02 * (image_pixels / 1024) + 9.59e+01
...
>>> expected_memory_usage(256 * 1024)
115.97040000000001
>>> expected_memory_usage(4096 * 1024)
417.02639999999997
>>> expected_memory_usage(9999999 * 1024)
784095.8216
Now you can estimate memory usage for any input size, from tiny to huge.
Practical considerations
Peak resident memory is not the same as peak memory usage
What we’re measuring above is how much memory is stored in RAM at peak. If your program starts swapping, offloading memory to disk, peak memory usage might be higher than resident memory.
So be careful if you start seeing peak resident memory usage plateau, as this may be a sign of swapping.
You can use psutil to get more extensive current memory usage, including swap.
You will however need to do some polling in a thread or other process as your program runs, since this doesn’t give you the peak value.
Alternatively, just make sure you gather your estimates on a computer with more than enough RAM.
Add a fudge factor
While the model will often give you a reasonable estimate, don’t assume it’s exactly right. You’ll want to add another 10% or more to the estimate as a fudge factor, because real memory usage might vary somewhat.
In other words, if the model says you need 800MB RAM, make sure there’s 900MB free.
Memory usage may not be linear
In many cases peak memory requirements scale linearly with input size. But that’s not always the case: make sure your model isn’t making false assumptions, and underestimating memory usage for large inputs.
When to consider optimizing memory usage
Once you have a good estimate of how memory usage varies based on input size, you can think about cost estimates for hardware, and therefore the need for optimization.
Large datasets combined with faster-than-linear memory requirement curve are a bad combination: at a minimum you’ll want some form of batching, but changes to your algorithms might also be a good idea.
