Beware of misleading GPU vs CPU benchmarks
Do you use NumPy, Pandas, or scikit-learn and want to get faster results? Nvidia has created GPU-based replacements for each of these with the shared promise of extra speed.
For example, if you visit the front page of NVidia’s RAPIDS project, you’ll see benchmarks showing cuDF, a GPU-based Pandas replacement, is 15× to 80× faster than Pandas!
Unfortunately, while those speed-ups are impressive, they are also misleading. GPU-based libraries might be the answer to your performance problems… or they might be an an unnecessary and expensive distraction.
Problem #1: Comparing against a single CPU core
Those benchmarks showing cuDF is 15× to 80× faster than Pandas may be accurate, but they’re comparing against Pandas running on a single CPU core. Specifically, the RAPIDS page says the Pandas benchmark is running on a single core of an AMD EPYC 7642, a CPU that has 48 physical cores.
Now, to be fair, the Pandas library is single-threaded. But fixing that doesn’t require using a GPU! Parallelism is what makes GPUs fast, so if the GPU implementations are fast, it’s likely a parallel CPU implementation could be faster as well. Some options include:
- Using a wrapper like Dask, that automatically parallelizes the algorithm across multiple cores.
- If you are processing many different independent files, you can manually start a process pool running multiple copies of your end-to-end algorithm.
- Or, you can use alternative dataframe library that natively takes advantage of multiple cores.
A better comparison
If you click through to the cuDF documentation you’ll find a more reasonable benchmark (image copyright Nvidia, under the Apache license):
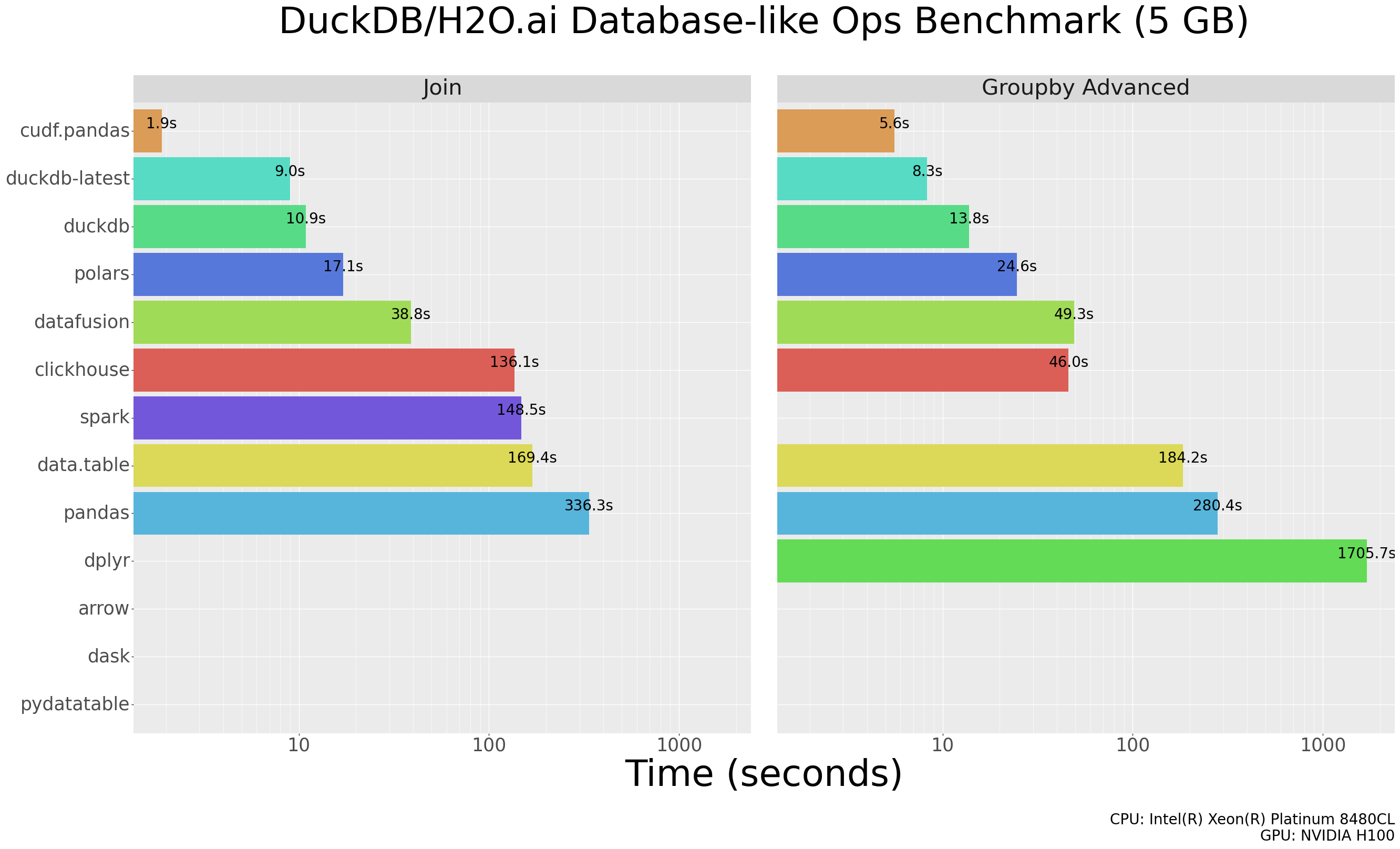
In particular, it includes libraries like DuckDB and Polars that are able to transparently take advantage of multiple CPU cores. Compared to DuckDB running on a CPU, cuDF running on a GPU gives speed-ups of 1.5× to 5×: a significant improvement, but much less than 17×-300× speedups when cuDF is compared to Pandas for the same task.
It’s also worth noticing the spread in performance across the different CPU-based libraries, even those that can use multiple cores. Algorithms, architecture, and API design clearly can make a big difference in performance, not just type of hardware.
Problem #2: Ignoring cost
GPU-based computation is clearly faster than multi-core CPU-based computation for the hardware used in the comparison above. But that computing hardware doesn’t come for free; one way or another you will need to pay for it. So how do the prices compare?
The dataframe benchmarks are run with a Xeon Platinum 8480CL, which is hard to find prices for, and an Nvidia H100. So below I show the price for an AMD Ryzen Threadripper PRO 7995WX, which is somewhere between the same speed and 0.75× the speed of the 840CL (based on Geekbench numbers).
| Type | Model | Cost (Jan 2024) |
|---|---|---|
| CPU | AMD Ryzen Threadripper PRO 7995WX | $10,000 |
| GPU | Nvidia H100 | $30,000 |
So yes, switching to a GPU will give you a 1.5× to 5× improvement in speed… but you will need to pay 2× to 3× as much money for that speed-up.
Are GPUs worth it?
It’s difficult to say in general whether how much faster a GPU-based solution will be, or if it’s cost effective. Different computing tasks, CPU models, and GPU models will give you different speeds and different costs, resulting in different trade-offs. And that’s before you take into account the problem with GPUs compared to CPU-based implementations: the limited computing model, additional difficulties in development (your CI machine will need a GPU too!), and lack of portability.
Depending on your particular problem, GPUs may be an amazing solution—or they might be an expensive waste of time compared to the alternatives. So look past the misleading benchmarks, and do the experiments to figure out if GPUs are right for your use case and budget.
